目录
最近一段时间太忙了,忙到所有的计划被打的粉碎,算了,能做多少做多少,想到什么写什么吧🤣🤣🤣。生产力来自于需求,发现最近记录的东西都是加快搬砖速度的,这次也是。某东的域名太多了,偶然发现有些域名的map不对,于是就想到用DNA来批量获取配置校验一下,问题是一个个的做太慢了,全部都并行将近一千个子进程,又怕一下把服务器打挂了。于是,控制并发数量就显得很有必要。还有就是最近在做一些已有功能的重复实现,比如Huang的pz,Lin的idlog以及rip,前后差不多快两个星期的时间,还是仿出来了,在仿照他们的功能的过程中,遇到了一些有意思的问题,好在也都解决了,其中用到的小技巧也记录一下。待办事项是ssl检验以及urlmd5值校验(包括内容比对),这两个等有时间再说,先挖个坑。
在进入主题前,需要了解一个事实,那就是Bash其实并不适合做多进程或者多线程的操作,某些特殊情况下,是可以做一下优化,比如重复执行批量的,独立的命令时,利用一些技巧,就可以实现“时”半功倍。而本篇也不只是记录bash多线程作业,还包括其他有用的技巧。
一、获取脚本/程序运行数目
很多监控类型的脚本,在运行的时候都需要先看一下该脚本有无运行——后续以background.sh来指代,以及对应的PID是什么,是否需要先kill掉等。可以分为两种情况,一种是在另一个脚本——monitor.sh中获取,另一种方案是在backgound.sh脚本本身中获取。
1. 在monitor.sh中获取
这种方式比较直接,使用ps命令可以很准确的过滤出相关信息。运行background.sh的同时,运行monitor.sh就可以获取前者的运行状态以及当前有几个脚本在运行。
bash###### Here is background.sh ######
#!/bin/bash
while [[ 1 == 1 ]]; do
echo
sleep 1
done
###### Here is monitor.sh ######
#!/bin/bash
ps -ef | grep background.sh |grep -v 'grep'
number=`ps -ef | grep background.sh |grep -v 'grep' | wc -l`
echo "There is/are $number program(s) running for now"
2. 在background.sh本身获取
相比较与使用monitor.sh来获取脚本的运行状态,有时候我们不想那么麻烦,就想直接在当前脚本中获取当前脚本的运行状态,以便做进一步的处理,直观来想,应该和第一种方式完全一样才对,可实际情况却不太一样,例如,现在尝试在终端运行如下:
bash#!/bin/bash
while [[ 1 == 1 ]]; do
echo
sleep 1
ps -ef | grep background.sh |grep -v 'grep'
number=`ps -ef | grep background.sh |grep -v 'grep' | wc -l`
echo "There is/are $number program(s) running for now"
done
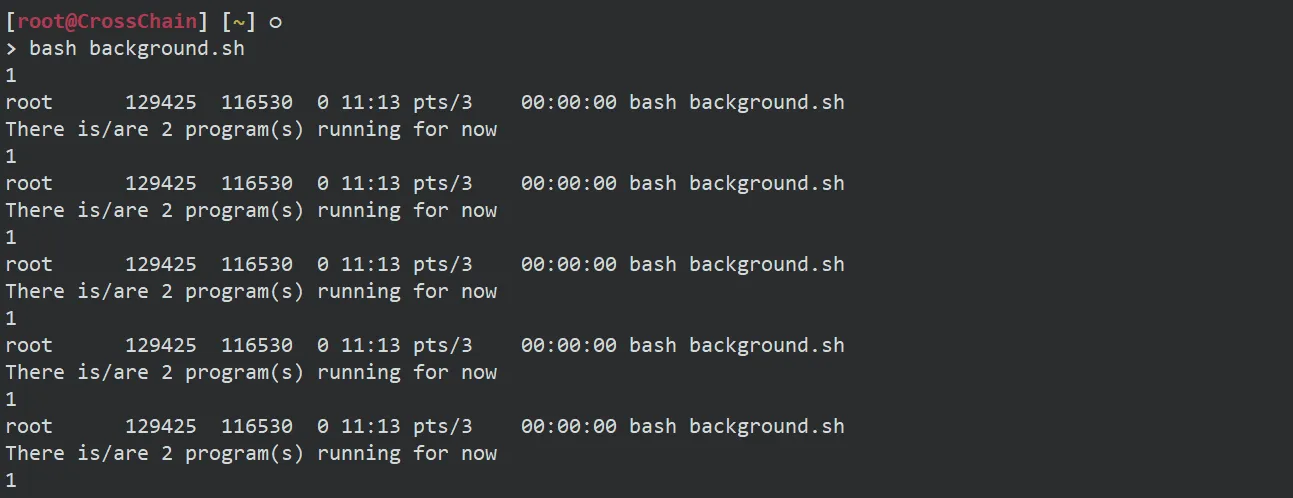
可以看出使用ps命令获取的进程信息是正确的,但是使用wc -l命令获取的进程数量是不对的,多个终端同时运行,也是一样的结果。所以如果想要使用ps命令在脚本本身获取脚本的运行状态,可行的方案是,将ps命令的输出写入一个文本,然后通过文本内容进一步判断:
bash#!/bin/bash
while [[ 1 == 1 ]]; do
echo
sleep 1
ps -ef | grep background.sh |grep -v 'grep' > $$.count
cat $$.count
number=`cat $$.count | wc -l`
echo "There is/are $number program(s) running for now"
done
二、时间形式转换
Linux系统下输出时间的命令很容易想到,就是date,基本用法无非就是输出年月日时分秒,日期时间转换成秒是很容易做到的,有两个稍微特殊点的问题:
- 如何把一个指定时间转换成成秒
- 如何把一个指定秒数转换成年月日时分秒
date命令获取纳秒
bash# 把一个指定时间转换成成秒
# date -d "$year-$month-$day $hour:$minute:$second" +%s
$ date -d "2022-06-26 12:00:00" +%s
$ 1656216000
# 把一个指定秒数转换成年月日时分秒
# date -d@$((second-0)) +'%Y-%m-%d %H:%M:%S'
$ date -d@1656216000 +'%Y-%m-%d %H:%M:%S'
$ 2022-06-26 12:00:00
# `date`命令获取纳秒,可以用来做更细精度的唯一检验码
date +%s%N
三、多进程并发执行
多数情况下,我们使用bash脚本基本都是串行执行的,也即从上到下依次执行。极少的使用场景,比如需要循环处理大量相同类型的需求时,一个一个的处理太慢了,需要使用一个循环语句,将这些需求放在后台并行执行;又或者某个任务需要很长时间才能完成,比如压缩比较大的目录,为了充分发挥CPU的能效,需要将任务设置成多进程工作。
场景模拟
为了方便阐述,使用一段测试代码。在这段代码中,通过seq命令输出1到10,使用for...in...语句产生一个执行10次的循环。每一次循环都执行sleep 1使整个事件看起来执行了一段时间,并echo出当前循环对应的数字。实际应用场景其实也是差不多的,把需要处理的内容替换掉echo语句即可。
bash#!/bin/bash
TS=`date +%s`
for num in `seq 1 10`; do
echo -n "${num} "
sleep 1
done
echo
TE=`date +%s`
echo "Start Time: `date -d@$TS +'%Y-%m-%d %H:%M:%S'`"
echo "End Time : `date -d@$TE +'%Y-%m-%d %H:%M:%S'`"
echo "Duration : $((TE-TS)) seconds"
# 如上是程序,如下是执行过程
[ 0 root@tencent ~]# bash serial.sh
1 2 3 4 5 6 7 8 9 10
Start Time: 2023-05-29 09:29:32
End Time : 2023-05-29 09:29:42
Duration : 10 seconds
可以很容易看出循环了10次,每次sleep 1,依次输出1~10的数字,而echo命令的时间可以忽略不计,所以总的执行时间是10s,此时程序是串行执行的,没有做任何的优化。
方案一:使用& + wait命令让程序后台运行
&符号或者成为命令放在其他命令的最后面就能让其他命令放在后台运行,而非显式的阻塞显示屏输出。
bash#!/bin/bash
TS=`date +%s`
for num in `seq 1 10`; do
{
echo -n "${num} "
sleep 1
} &
done
wait && echo
TE=`date +%s`
echo "Start Time: `date -d@$TS +'%Y-%m-%d %H:%M:%S'`"
echo "End Time : `date -d@$TE +'%Y-%m-%d %H:%M:%S'`"
echo "Duration : $((TE-TS)) seconds"
# 如上是程序,如下是执行过程
[ 0 root@tencent ~]# bash parallel.sh
1 3 2 6 7 8 5 10 9 4
Start Time: 2023-05-29 09:32:46
End Time : 2023-05-29 09:32:47
Duration : 1 seconds
首先几乎是人眼察觉不到的即时输出,因为有sleep 1和wait的设定,总体延时是1s,其次输出形式不唯一,意思是每次运行程序的输出结果顺序不同。这是因为循环体内的命令全部进入后台,所以十次循环体均是先打印输出一个数字和一个空格之后,再sleep了1秒之后结束后台命令。所以跟人的感觉就是立马得到了输出,即循环体的执行时间为1秒钟,这是由于循环体在后台执行,没有占用脚本主进程的时间。
这种方式可以做到多进程同时运行,但无法控制并发数量,适用于并发较少,且任务彼此之前无相关性,对输出结果顺序不做要求的情景。
方案二:使用文件描述符控制并发数
如下脚本是一个可以控制线程并发的案例,使用的是文件描述符和重定向功能来实现的,需求背景是,“有一个文件url.list存储了几百条url,现在相对每一条url做curl请求,以获取url对应的文件大小,并存储到size.log文件内,最后对改文件url大小列做排序”。
bash#!/bin/bash
# 要并发执行的函数
function CMD() {
size=`curl -sI "$line" | grep -i "Content-Length" | awk -F ':' '{print $2}' | sed 's/\r//g'`
while [[ 1 == 1 ]]; do
if [[ $flg -eq 1 ]]; then
sleep 0.2
continue
else
let flg=1
echo $size' '$line >> urlSize.log
let flg=0
break
fi
done
}
# 接收一个参数
[[ $# -ne 1 ]] && { echo -e "Usage:\n bash $0 filename"; exit 222; }
# 判断文件是否存在
filename=$1
! [[ -e $filename && -f $filename ]] && { echo "$filename is not a file, need a valid file containing urls"; exit 223; }
> urlSize.log
let flg=0
tfifo="$$.fifo" # 以PID为名, 防止创建命名管道时与已有文件重名,从而失败
mkfifo $tfifo # 创建命名管道,不能是普通文件
exec 7<>$tfifo # 以读写方式打开命名管道, 文件标识符fd为7
rm -rf $tfifo # 删除文件, 也可不删除, 不影响后面操作
Nproc=10 # 并发进程数
# 初始化管道
for((i=1; i<=$Nproc; i++)); do
echo
done >&7
# 使用循环处理控制并发
while read line; do
# 领取令牌, 即从fd7中读取行, 每次一行,对管道,读一行便少一行,每次只能读取一行
# 所有行读取完毕, 执行挂起, 直到管道再次有可读行,因此实现了进程数量控制
read -u 7
{
# 要批量执行的命令放在大括号内, 后台运行,可使用判断子进程成功与否的语句
# CMD && echo "[Finished] $line" || echo "[Failed] $line"
CMD
sleep 0.2 # 暂停若干时间,可根据需要适当延长,给系统缓冲时间
echo >&7 # 归还令牌, 即进程结束后,再写入一行,使挂起的循环继续执行
} &
done < $filename
wait # 等待所有的后台子进程结束
exec 7>&- # 删除文件标识符
cat urlSize.log | sort -nk1 -k2 > size.log
rm urlSize.log
cat size.log | awk '$1 >= 500000000 {print $2}' > ge500M.log # 大于等于500M的文件
cat size.log | awk '$1 < 500000000 {print $2}' > lt500M.log # 小于500M的文件
该需求比其他一般需求较为复杂,涉及到将并行执行的结果写入文件,因此文件写入的时候会有同事写入的情况,需要避免,通常思路是设定文件锁,以避免同时写入;另外一种思路就是,将需要写入的内容存入一个数组,最后将数组中的数据一次写入文件。
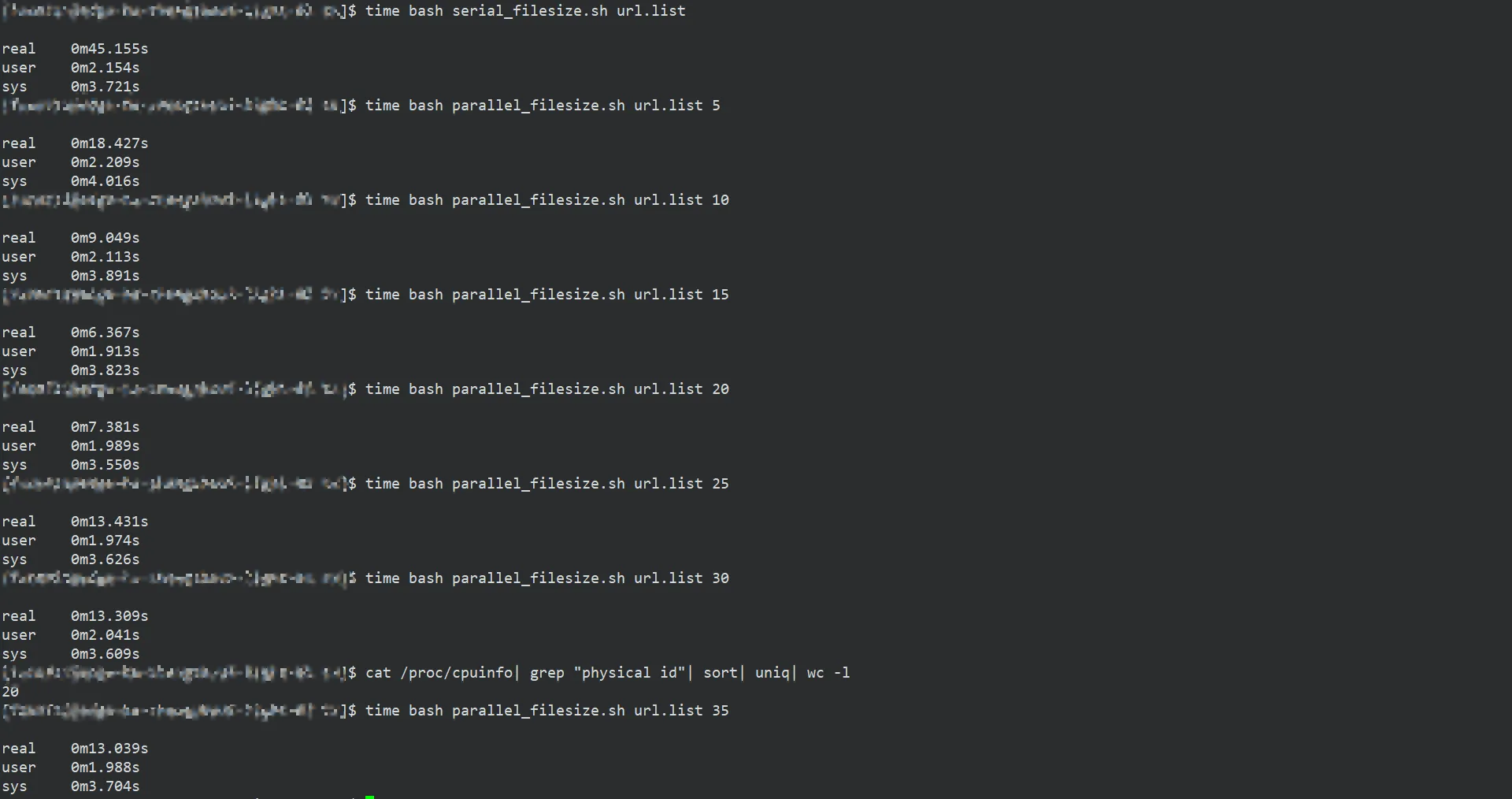
从上图可以看出,并不是并发数设定的多高越好,需要考虑服务器CPU的核数以及运算能力等等
方案三:使用xargs -P控制并发数
xargs命令是给命令传递参数的一个过滤器,也是组合多个命令的一个工具,英文全拼是eXtended ARGuments,可以将管道或标准输入(stdin)数据转换成命令行参数,也能够从文件的输出中读取数据,也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。 默认的命令是 echo,这意味着通过管道传递给 xargs 的输入将会包含换行和空白,不过通过 xargs 的处理,换行和空白将被空格取代。是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。
之所以能用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中有有这个必要,所以就有了 xargs 命令,例如:
bashfind /sbin -perm +700 |ls -l #这个命令是错误的
find /sbin -perm +700 |xargs ls -l #这样才是正确的
xargs 一般是和管道一起使用
关于使用xargs命令并行处理的示例,可以通过参考文档中的链接来了解一下,暂时没有相关的使用场景。如下是对该命令用作并行执行的汇总,也是摘抄自参考文档:
- 如果只有单核心cpu,想提高效率,没门
- xargs的高效来自于处理多个文件,如果你只有一个大文件,那么需要将它切割成多个小片段
- 由于是多进程并行处理不同的文件,所以命令的多行输出结果中,顺序可能会比较随机
- xargs提升效率的本质是cpu的利用率,因此会有内存、磁盘速度的瓶颈。如果内存小,或者磁盘速度慢(将因为加载数据到内存而长时间处于io等待的睡眠状态),xargs的并行处理基本无效。
方案四:使用GNU parallel命令控制并发数
parallel是一个是一个开源的命令行工具,可以将多个命令行作业并行执行,适用场景为处理大量的命令行作业,例如搜索文件、处理数据、编译代码等等。它可以用于在多个CPU或计算机上同时运行命令行作业,从而提高作业处理速度。Parallel还可以帮助您更好地利用系统资源,节省时间和精力。
具体示例待补充
该命令与xargs类似,都是非常好的工具,但是均有如下需要注意的点:
- 学习曲线较陡: GNU Parallel的使用需要一定的学习曲线,特别是在使用高级功能时。这需要您花费一些时间和精力来学习和掌握
- 可能存在并发问题: 由于GNU Parallel是一个并发计算工具,可能存在一些并发问题,例如竞争条件、死锁和资源争用等。这需要您在使用时进行注意和处理,以避免出现问题
- 需要足够的系统资源: 由于GNU Parallel需要利用多个CPU核心和计算机节点来执行作业,因此需要足够的系统资源来支持。如果您的系统资源较为有限,可能会影响作业的执行效率和质量
- 可能存在数据依赖性问题: 由于GNU Parallel是并行执行作业的,因此可能会存在数据依赖性问题,例如某些作业需要依赖于其他作业的输出。这需要您在使用时进行注意和处理,以避免出现问题
四、trap命令
trap命令用于指定在接收到信号后将要采取的动作,常见的用途是在脚本程序被中断时完成清理工作。该命令de语法是trap [-lp] [[arg] signal_spec ...],当Shell接收到signal spec指定的信号时,arg参数(命令)将会被读取,并被执行。例如:
bash#=======================================================================================
# 功能:捕获 Ctrl + C 将后台进程全部终止
# 入参:bg_pids, progress_pid
# 出参:None
function onCtrlC () {
exec 3>&2 # 3 is now a copy of 2
exec 2> /dev/null # 2 now points to /dev/null
kill ${bg_pids} ${progress_pid} >/dev/null 2>&1
sleep 1 # sleep to wait for process to die
exec 2>&3 # restore stderr to saved
exec 3>&- # close saved version
echo -e "${c_bir}IDS!\n${c_e}"
echo -e "${c_bir}[IDS-100] Ctrl+C is captured, exiting...\n${c_e}"
exit 100
}
#=======================================================================================
# 功能:捕获 `exit` 退出指令,并计算脚本实际运行时间
# 入参:TS
# 出参:None
function onExit () {
local te=`date +%s`
echo -e "${c_bib}Start Time: $(date -d@$((ts-0)) +'%Y-%m-%d %H:%M:%S')"
echo -e "${c_bib}End Time : `date +'%Y-%m-%d %H:%M:%S'`"
echo -e "${c_bib}Duration : $((te-ts)) seconds\n${c_e}"
}
# 正常退出时触发
trap 'onExit' EXIT
# 捕获Ctrl+C时触发
trap 'onCtrlC' SIGINT
通常情况下,可以通过trap -l来获取当前系统支持的signal spec列表,常用的有如下,需要注意的是EXIT这个信号并没有明确定义,但实际存在,且值为0:
| 值 | 信号 | 描述 |
|---|---|---|
| 0 | EXIT | 一切退出的命令 -- exit XXX,都会触发 |
| 1 | SIGHUP | 挂起,通常因终端掉线或用户退出而引发 |
| 2 | SIGINT | 中断,通常因按下 Ctrl+C 组合件而引发 |
| 3 | SIGQUIT | 退出。通常因按下 Ctrl+\ 组合键而引发 |
| 6 | SIGABRT | 中止,通常因某些严重的执行错误而引发 |
| 9 | SIGKILL | 立即结束程序的运行,不能被阻塞处理和忽略,kill -9 PID触发,但无法被捕获 |
| 14 | SIGALRM | 报警,通常用来处理超时 |
| 15 | SIGTERM | 终止,通常在系统关机时发送,kill PID触发 |
| 20 | SIGTSTP | 停止进程的运行,但该信号可以被处理和忽略,通常因按下 Ctrl+z 组合键而引发 |
五、基于PID的进度条实现
进度条的实现有很多种方式,不局限于语言的话,Python已经有很多已经实现的库了,针对于Shell,进度条的实现根据判定条件也是有不同的方案,如下是一个通过判断PIDs是否完成来实现的进度条,如果输出完一行之后,后台程序还未完全结束,会继续重新输出。
bash#!/bin/bash
function progress() {
prompt='Ongoing: '
ratio=1
# ps -p pidlist命令的作用是列出pidlist里面所有pid的运行状态,已经结束的pid将不会被列出,每个pid一行
while [[ "$(ps -p ${bg_pids} | wc -l)" -ne 1 ]]; do
let width=`tput cols`
let length=width-${#prompt}-1
mark='>'
progress_bar=''
# 小于ratio的部分填充'>',大于ratio的部分,填充' ',必须是空格,不然ratio重新变成1的时候,没有变化
for i in $(seq 1 $length); do
if [[ $i -gt $ratio ]]; then
mark=' '
fi
progress_bar="${progress_bar}${mark}"
done
echo -ne "$prompt${progress_bar}\r${c_e}"
ratio=$((ratio+1))
if [[ $ratio -gt $length ]]; then
ratio=1
fi
sleep 1
done
}
for((i=0;i<=10;i++)); do
{
wait_ts=$((RANDOM%200))
sleep $wait_ts
} &
bg_pids=$bg_pids' '$(jobs -p | tail -1)
done
progress $bg_pids
wait
echo 'done'
六、文件描述符
Linux中一切皆文件,比如C++源文件、视频文件、Shell脚本、可执行文件等,就连键盘、显示器、鼠标等硬件设备也都是文件。一个Linux进程可以打开成百上千个仙相同的或者不同的文件,为了表示和区分已经打开的相同文件,Linux会给每个文件分配一个编号(一个ID),这个编号就是一个整数,被称为文件描述符(File Descriptor)。
文件描述符的底层原理是非常精妙的,可以参考相关文档,使用文件描述符,主要是为了让输出或者写入按照我们自己的想法来操作:
| 操作 | 描述 |
|---|---|
| > log.txt | 相当于echo "" > log.txt |
| exec 8>&1 | 将STDOUT 1 复制到描述符8,相当于备份 |
| exec 9>&2 | 将STDERR 2 复制到描述符9,相当于备份 |
| exec 1> /dev/null | 将标准输出,定向到NULL |
| exec 2> /dev/null | 将标准错误,定向到NULL |
| exec 1>&8 | 恢复STDOUT |
| exec 2>&9 | 恢复STDERR |
| exec 8>&- | 关闭描述符8 |
| exec 7<log.txt | 以只读的方式打开,对应文件描述符是7 |
| exec 7>log.txt | 以只写的方式打开,对应文件描述符是7 |
| exec 7<>log.txt | 以读写的方式打开,对应文件描述符是7 |
七、不登录服务器执行命令
有些时候需要在服务器上执行一个命令,但是不想登录服务器去操作,就可以使用如下方式,执行完之后立即退出,也可以选择将输出的结果,存放在文件中。如下命令行,表示查看1.1.1.1主机上的ssh config文件,并退出登录。
bashssh -o ConnectTimeout=60 1.1.1.1 "cat /root/.ssh/config"
参考文档


本文作者:Manford Fan
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!